Table of Contents
Victory!
First things first
And now for something completely different
Lost in endless time
Professional courtesy
The Next Generation
A plethora of options
Ay, there’s the rub
It’s not for you
Back to your turnips!
It’s over 9000!
I could help you do that better
Trashercise
Tautology Club
Fair And Balanced
WebP
HEIC
No.
AVIF
Hi. I’m the JPEG organization.
Generation loss
Fast Fashion
Nature and nurture
But in the end, it doesn’t even matter
With malice aforethought
The bazaar
I’m not dead. I feel fine!
Appendices
Compressing on your Android phone
Compressing audio
Compressing DVD video
Compressing modern video on Android
Compressing modern video on Windows
Compressing images to JPEG XL
Compressing images to WebP
Compressing images to AVIF
Soundtrack comparison
Image sources
The format wars are over. And we won!
Victory!
Unfortunately, we also lost. It depends on your perspective, priorities, technical knowledge, professional industry, and so on. For most people, it’s mostly a win. But I am not most people, and if you’re reading this article, then neither are you!
First things first
What is a format? What is a format war? And why do we care? Briefly put, a format is a specified structure of some kind of media content, such as images or audio, and a format war is the inconvenient truth that it’s unrealistic to use every format every time, which leads to competition and – sometimes lamentably – attrition. One of the earliest modern examples of a format war is the videotape format war between VHS and Beta. They were two quite similar products to serve the same basic purpose, but still proprietary and incompatible with each other. A VHS player couldn’t play a Beta tape and vice versa, and they were initially quite expensive, so most families had to choose just one. Beta tapes allowed for higher quality video but not as much recording time, which was a key factor (along with marketing, most likely) in the VHS format’s rise to dominance. More VHS players meant more incentive to focus on VHS tapes, which meant more reason to buy a VHS player, and this feedback loop spelled the end of the Beta format – or at least, of Betamax, meant for the consumer market. Betacam, meant for the professional market, remained in use for many years. Years later, we had the privilege of enduring another format war, this time for high-definition video. Did you get an HD DVD player or a Blu-Ray player? If you made the wrong choice, you’d be stuck with a stagnant library while all new releases went to the winning format. The winner of that war was Blu-Ray, largely due to its use in the PlayStation 3, which was cheaper than most high-definition video players and served as a gaming console to boot.
And now for something completely different
Well, not completely different, per se, but I quite enjoy putting little jokes and references into these headings.
Cassettes and discs of various types are physical media formats, but there are also formats for describing just the data themselves, used in computing. Even the least computer-savvy among us is familiar with at least a few of these, like JPEG for photos and MP3 for music. These formats provide a sort of standard packaging for a file’s data, and they’re also accompanied by a corresponding “codec” which tells the computer how to enCOde or DECode those data. Note that this isn’t the secret kind of code, but simply the representation and conversion of information. There are formats and codecs or encodings for text, images, audio, video, file archives, typesetting, and everything else under the sun.
But, what actually is a format or encoding? Like, what is it? Let’s get down to the nuts and bolts with a simplified example of an image format and codec. Computers show images as a grid of appropriately-colored pixels, so our format could tell a computer about an image by first providing the dimensions of the image and then describing each pixel, one at a time, by its colors. Our codec will use the colors red, green, and blue, which can combine to show any shade (commonly referred to as RGB). Each color will have a value of 0 through 9, for a total of 1,000 possible colors. So, if our codec is given an image to encode, it will first write down the dimensions, such as 640 pixels wide by 480 pixels tall, and then continue with e.g. 000 for a black pixel or 770 for a dark yellow pixel, until we’ve described every pixel. Once we have an image file constructed in our format and its data specified by our codec, we can give this file to a photo gallery program. The program will look for the image data using the format’s specifications, and then use a decoder for our codec that instructs it how to read the image dimensions, then read three digits at a time for each pixel until it’s complete. The program will use this information to show us the image.
You may have noticed some flaws in our format and its codec. How exactly do we specify the dimensions? How large can each dimension be? What if we want more precise colors (common displays are capable of 16.7 million colors)? We didn’t consider things like transparency, either. Even worse, there’s no compression of any kind, so file sizes would scale linearly with the number of pixels in the image, regardless of the image’s complexity. With our simple format, a completely black image that was ten million pixels wide and tall would be a gigantic file to store and manipulate even though I just described it with just a few English words. This is why there are so many formats and codecs: each one has different strengths and weaknesses, features and failings. The ASCII text format is simpler and smaller than Unicode, but Unicode can handle many more unique characters. The BMP image format stores every pixel exactly as intended, a little like our example format, which results in large files. The JPEG image format can compress images for excellent file size savings, but it does this by preserving only an approximation of the original image, so some details are discarded and lost.
Lost in endless time
Let’s continue by casting our gaze into the misty depths of forgotten history. To be more specific, that would be 2007, which is sufficiently ancient that we may firmly consider it antiquity for our purposes. I wrote this guide to DVD archival on October 30, 2007, judging by the date of last modification on its image files. At that point in my life, I was studying for a degree in technical writing, but I don’t believe I wrote this guide for that. I also had a Geocities site, but I don’t think I uploaded it there, especially given the rather stringent storage and bandwidth quotas. And yet, it’s an HTML document. Why? Perhaps I was simply keeping my skills sharp with Dreamweaver MX 2004, a graphical web design tool that I’d learned in high school a couple years prior. Alas, the world may never know my motivations with certainty.
Suffice it to say, it was an ugly process with ugly results that were ugly. But that’s what I did! And I recommended it, too (albeit to no one in particular, as my content doesn’t exactly command the biggest readership around). I still have rips of DVDs from this time period, when I’d buy DVDs online not from Amazon but from Deep Discount DVD, which doesn’t exist anymore but they had decent prices and I think their mascot was some kind of anthropomorphic illustrated shark.
Actually, upon further research via The Internet Archive, I’m partly wrong. Deep Discount DVD no longer exists, because they became Deep Discount when they started offering other products like books and clothing. Fortunately, I was right about the shark:

That logo is no longer in use, but it’s still a shark!

Ah, nostalgia.
Anyway, those rips are low-resolution (480 by 320, twice the width and height of YouTube’s lowest available resolution), filled with motion artifacting, and with a tendency for audio sync to drift over time due to frame rates or something. To translate into plain English for non-technical users who probably aren’t reading this article, they’re fuzzy, they occasionally have weird glitches in some areas, and sounds happen further and further away from their visuals as the episode or movie progresses. To top it all off, the files are really large, comparable with modern HD video. That was the best we could do with good old DivX 3.11a, and it sufficed for me. Whenever I wanted to watch those videos, I could just push a few buttons on my computer without having to pull out any DVDs, which also minimized opportunities to scratch the discs. This format was also compatible with the superlatively excellent Cowon A2, a portable media player from the mid-aughts which I still have to this day. This meant that I could watch my DVDs anywhere I wanted, quite a treat for long flights.
It’s worth mentioning the audio as well as the video. The audio, fortunately, wasn’t nearly as ugly. The MP3 codec can take uncompressed CD-quality music and squeeze it down (with some data loss, like JPEG) as much as you want – a fifth of its original size while maintaining very good quality, a tenth of its original size while maintaining decent quality, even a twentieth of its original size at a quality that’s mediocre at best but still usable, especially for less complex audio like speech. This is done by specifying a target bit rate, simply how many bits of data are used for a given duration of content (almost always one second), usually expressed these days with SI prefixes like kbps for kilobits per second so that the numbers don’t get too unwieldy. Note that these are bits, not bytes, meaning just the smallest unit of binary information, which can take a value of 0 or 1. A byte is a group of eight bits, so you’ll need to keep this in mind if you’re working with both. One second of audio at 80 kilobits per second would thus have a file size of 10 kilobytes. This particular value is pretty low quality with the MP3 codec. The most commonly used bit rate is 128 kbps. People willing to sacrifice storage space for better quality might use 256 kbps or even more. Most devices can handle up to 320 kbps, and the format theoretically allows up to 640 kbps, but there are codecs with lossless compression algorithms (expressing data more compactly without discarding any of it) that can achieve lower bit rates than that anyway, so there’s not much point. The most common lossless audio format and codec these days is the Free Lossless Audio Codec, FLAC.
Professional courtesy
A lawyer is sailing a small boat when a particularly boisterous wave tosses him into shark-infested waters. It takes time for the rescuers to arrive, and they fear the worst, but they pull him aboard unharmed. “Why didn’t the sharks attack you?” they ask. The lawyer answers, “professional courtesy."
Get it? Because lawyers are sharks. The American Bar Association monitored all lawyer action in this article and no lawyers’ feelings were harmed in the making of this joke, because they don’t have any. Get it? Again? Lawyers. The ABA didn’t actually monitor this article, it’s a joke, please don’t sue.
The point of all that was to dive into that little word in Free Lossless Audio Codec: “Free.” Some codecs are not free. Developing a codec can be very complex, and their creators would like to be compensated for their work, so they patent said work. If a third party wants to make hardware or software that can handle that codec, they need to pay licensing fees to the creators and/or implement it themselves. Unlike a novel gearing mechanism or radio antenna, the whole point of a format or codec is to allow different systems to work together, so adoption rates matter. Using a patented system can cause legal issues, ranging from simply paying licensing fees to being sued for using the patented system in an unlicensed way. This can drive away potential users, making it more difficult to find compatible equipment and leading to such codecs being called “patent-encumbered,” as these legal issues encumber a codec’s popularity and practicality. Thus, a patent-encumbered codec has to be quite good to gain any adoption, much less widespread use. There are actually quite a few patented codecs with varying degrees of popularity, notably the MP3 codec, which was patented by its original creators, with various other related patented works from other entities. It was a very competitive codec at the time from a technical standpoint, so it was widely licensed. Some organizations created free implementations of the MP3 codec, and subsequently encountered legal issues. The developers of the LAME MP3 encoder, one of the most capable and popular free MP3 encoders used by consumers, could only officially distribute source code, so the burden fell to users to dig around for a compiled executable and install it into whatever software we wanted to use rather than simply using something that worked out of the box. All related patents have since expired, but it was quite a hassle back then, and it’s not a state-of-the-art codec anymore anyway. The fact that the length of a patent term can easily cover the vast majority of a tech product’s useful life is another issue entirely.
The Next Generation
Progress didn’t stop there. The Advanced Video Codec, AVC, soon became the most widely-used video codec worldwide, patented but with several convenient licensing concessions. It can be used for free when streaming video to end users who view for free, there are open-source encoders whose licensing is already taken care of, and so on. It has pretty much universal device and software support, doesn’t take very powerful hardware to decode, can be encoded in real time in many use cases, and offers good quality and efficiency. It’s absolutely everywhere.
AVC is often combined with the Advanced Audio Codec, AAC, which offers better efficiency and features compared to MP3. As you might expect by now, it’s patented. Implementing a codec that adheres to the AAC specs requires licensing, but distributing AAC-encoded audio does not.
We’re not done, of course. The rise of streaming media has driven an absolutely enormous research effort into more efficient codecs and formats. Smaller files mean lower storage and bandwidth costs, which can translate into many millions of dollars at the mind-boggling scale at which YouTube and other large services operate. Audio now has the excellent Opus codec (lossy, free to use, extremely high quality). Video has HEVC, VP8, VP9, VVC, AV1... an embarrassment of selection. Image formats aren’t to be left out, of course, with WebP, AVIF, HEIF/HEIC, and JPEG XL seeing the most use besides older formats like JPEG, PNG, and GIF.
A plethora of options
Would you say we have a plethora of options? You would? We do? Well, what is a plethora? I would not like to think that a person would tell someone he has a plethora and find out that that person has no idea what it means to have a plethora. If you don’t know what it means to have a plethora of encoding options, you don’t know whether that’s good or bad.
Now that that reference has more than overstayed its welcome, we do have many options, but what used to be a good thing has turned sour. Standards are unicorns.
There’s a theory that you can cure this by following standards, except there are more “standards” than there are things computers can actually do, and these standards are all variously improved and maligned by the personal preferences of the people coding them, so no collection of code has ever made it into the real world without doing a few dozen identical things a few dozen not even remotely similar ways. The first few weeks of any job are just figuring out how a program works even if you’re familiar with every single language, framework, and standard that’s involved, because standards are unicorns.— Programming Sucks
Standards suffer from dilution. Attempts to unify and simply a situation end up adding to the complexity without removing anything. This isn’t unique to programming, computers, or even technology: Esperanto is a language initially created by a single designer in the late 1800s, L. L. Zamenhof. The goal was to allow Europe’s disparate cultural blocs to communicate in a single common language. There was just one problem: everyone already spoke a language, so Esperanto would mean a second language, and all those people would have to agree on it. In direct opposition to Zamenhof’s intentions, the world simply got yet another language. Today, it enjoys a small but enthusiastic following, albeit more as a novelty or curiosity than a practical communication tool. Learning a new language is hard, and most people won’t bother with one that doesn’t offer real-world opportunities for use.
Ay, there’s the rub
It’s a simple rub. Which option should we choose, and why? Formats and codecs are saturated far past the point of having the right tool for the job, like PNG images for synthetic content such as screenshots or JPG images for photographic content. There are multiple candidates vying for the exact same use cases, especially with video, where most features employed by any given codec are intended to make it look better while taking up less space. As long as it can be decoded at 1x or greater for playback on a significant enough fraction of devices, speed is barely an afterthought. The AV1 codec, like most codecs, has a reference implementation developed by its core designers (AOM, the Alliance for Open Media). Unlike most codecs, that reference implementation generally manages to encode video in approximately one one-thousandth of realtime. Yes, AOM’s AV1 encoder can take over 15 minutes for a clip just one second long, with a typical resolution and frame rate. Now consider how many seconds are in a movie. Or, more directly, go back to that factor of a thousand: a 90-minute feature-length film will tie up a machine for about 1500 hours, or two months. Fortunately, Intel has collaborated with Netflix to develop their own open-source implementation (SVT-AV1) that’s an order of magnitude faster. That’s right: you can now encode a movie at home in a mere week or so! Amazing! This is much better than the couple hours or so it took in 2006:
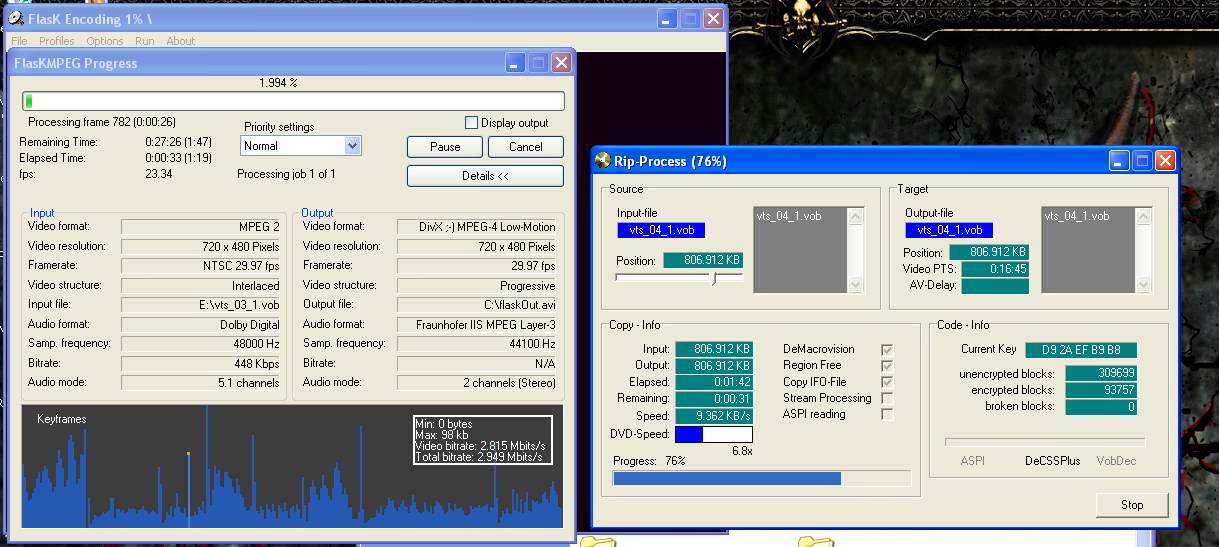
And, oh, how we used to suffer in 2011 when we got less than an hour to savor the encoding process!
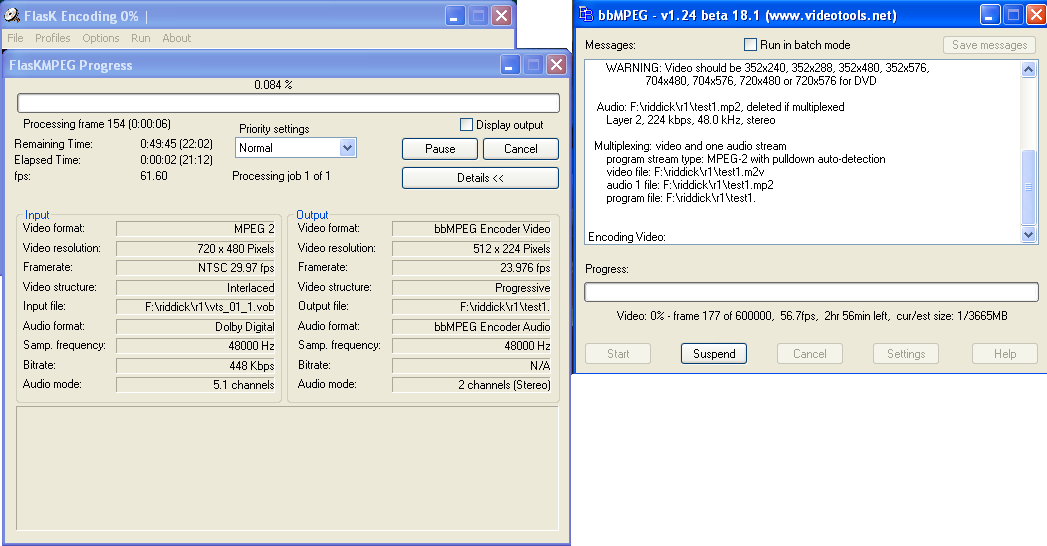
This is definitely what progress looks like for everyday consumers without access to giant server farms. Winning the format wars!
It’s not for you
Video codec development has, over the past decade or two, gradually swung from enthusiasts and hobbyists to industry titans. Netflix has the resources to encode their content in AV1 so they can save on storage and bandwidth. You don’t. It’s not for you. Even YouTube doesn’t have the resources to encode every video to AV1 – for now, only the really popular videos merit that kind of effort. If you want to make practical use of modern video codecs beyond just consuming content, you’ll need one of several specific modern graphics cards and a good deal of tweaking that lets you move the workload from the CPU to the GPU, which is more specialized but also much more powerful. Video encoding is an increasingly daunting task for the home user... and increasingly vital.
Consumer-captured media (still images, audio, and video) have exploded in popularity as the processes have gotten easier and cheaper, with better-quality results. Recording a home video no longer requires renting a camera and then storing the tape on a shelf. My current smartphone is a Samsung Galaxy Note 9, the company’s flagship model from almost five years ago, and it can shoot in 4K60. That’s 3840 by 2160 resolution at 60 frames per second, exactly 54 times the information density compared to the best efforts of my venerable Panasonic Lumix DMC-FZ50 from the mid-2000s, a mere 640 by 480 at 30 frames per second. Storing that much information is much easier than in the videotape days, but the numbers have obviously ballooned over the course of digital photography.
Back to your turnips!
Commoners and peasants toil away in electronic fields, while the landed gentry hoard technological developments. Insidiously, it isn’t a deliberate choice to artificially keep us down. It’s a simple result of the drivers of those developments having their own goals and not really caring about anyone else’s. YouTube and Netflix don’t mind taking a little while to compress their most popular content, but what of our digital photography that needs to encode video in real time? The solution, sadly, is to use very little compression. It’s the age-old problem of having to choose between speed, quality, and cost: for video capture, realtime speed is a hard requirement, and quality is the top metric that every layman can and will evaluate, so cost gets the short end of the stick. Ceteris paribus, more efficient video compression takes more encoding time, and so we can speed it up by increasing the allowed bit rate until it can encode in real time.
It’s over 9000!
Megabytes, that is, to record an hour and a half of 1080p30 video on an iPhone, even using the more-efficient HEVC rather than the typical AVC. I witnessed exactly this late last year (2022), when my parents filmed a friend’s bat mitzvah. The ceremony was about an hour and a half. The file is over nine gigs (9.222 gigabytes, or 8.588 gibibytes). How much storage do you have? Think beyond your PC with 12 terabytes of space across multiple drives (that’s my situation, anyway). The first place that has to store content captured by your phone is, obviously, your phone. How much room on there? 128 GB, maybe 256? Room for a microSD card to double that, perhaps? Now consider that you don’t want these files to be trapped in your phone. You want to transfer it to other devices, share it with other people, back it up in cloud storage, and so on. Well, your nine gig file is a nine gig file. That’s at least nine gigs!
My parents’ solution was to upload the file to iCloud, at which point they could download it onto their PC (yes, that was the least inconvenient method) and share the video with the bat mitzvah’s family, who also uses iCloud. I can only imagine and hope that, internally, Apple (actually, they subcontract their cloud service to Google Cloud rather than running their own, last I heard, so I’m not sure who’s doing what here) is merely linking to the same copy rather than duplicating the entire file. But then I wonder, how does that affect storage quotas? Does it all come out of the original owner’s? Or does it take nine gigs from anyone who saves the file to their account? Or is the storage quota burden split between them? I have no idea, and I suddenly don’t want to think about it anymore. The fact remains that it’s a nine gig file. And that’s simply a bit rate issue; shorter videos don’t get more efficient compression. 90 one-minute videos would take up just as much room.
I could help you do that better
I, being a scientist, was compelled – nay, contractually obligated – to meddle. My immediate and frantic inquest to learn the details, and my subsequent assessment of the problems we now faced, were met with nonplussed tolerance. But, as any scientist knows, one cannot let concerned stares drive one from the path to knowledge. After all, a mad scientist is still a scientist. Fortunately for my parents, or at least for my expectations of what they ought to care about, I’ve been doing this for a long time and have kept my hand in over the years. After uploading the original file to iCloud, and then downloading it back to my dad’s work computer (best possible CPU, couple hundred gigs of RAM – standard equipment for finite element analysis), I ran the command to process the file.
It took an entire day. As in, more than 24 hours.
And then we double-clicked the result to play it back and found that the colors were washed out.
After another day or two of frustrated research that involved short test encodings, Google searches of things like FFmpeg VP9 encoder supported bit depth and colorspaces, and a few rounds of Weather Game with various encoders and players, I finally found the problem. The Windows 10 default video player app doesn’t properly handle WebM VP9. The file worked properly in other video players.
So now we had an 825 MB file instead of a 9,222 MB file that we could share a lot more easily. It doesn’t really matter, since the only people interested in it already had access to it on iCloud, but now they have a more convenient copy for when bandwidth or storage space are concerns. The result is visually lossless, meaning that it doesn’t produce the exact same pixels of output as the original, and differences between corresponding frames can be rather easily spotted in a blink comparison at 250% zoom, but there’s no distinguishable quality loss in actual viewing. Of course, Apple being Apple, the default iOS video player doesn’t support this format, but VLC offers an iOS app that does (I’m sure there are other capable players as well). But I did it! Success!
Trashercise
There’s nothing quite like realizing that you’ve been duped into helping a corporation save money by doing their job for them at home for free. Why don’t companies like Apple provide any facility for compressing these ultra-high-bit rate videos? The answer is simple. As I said above, even YouTube doesn’t encode everything into AV1, reserving that for the very largest or most popular videos, because it’s a resource-intensive process. They don’t even want to devote the resources to create easy-to-use tools allowing users to do this on their own devices. They’ll do just enough to produce the files, and then leave users to figure out how to deal with these absolute storage and bandwidth hogs on our own, which usually means buying more storage and bandwidth, often from those selfsame companies.
Tautology Club
The first rule of Tautology Club is, of course, the first rule of Tautology Club, and we learn it when we try to explain to people why they should care about formats. KHInsider offers a huge repository of video game music, with most albums available in MP3 and FLAC, occasionally replacing one or both of these with other formats like M4A (the audio container format for AAC encoding) or Ogg. 99% of the files have extremely high bit rates for high quality, and 0% of the files are in Opus format which would save upwards of 50-70% compared to MP3 albums or 80-90% compared to FLAC. The cherry on top is that many albums aren’t copies of the game files, particularly for old systems that synthesize their music with the console’s proprietary sound chip. They’re simply recorded. And then uploaded in a lossless format. So an ancient game like Super Mario Bros. for NES has a 13 MB MP3 soundtrack or a 31 MB FLAC soundtrack, when the game itself is only 40 KB. That’s the whole game, including not only the music but also the sound effects, program code, and sprites. Emulators for these old systems are only a megabyte or two. Somehow, I suspect that not all of those 31 million bytes are absolutely necessary to represent the music.
And yet, even though the webmaster makes a big deal out of how much it costs to run the site and sells paid memberships to unlock features like downloading an entire album with a single click, I’ve tried and failed twice to convince him of how neat it would be to use a better and more modern codec. The first time, the response was that the bulk of the storage and bandwidth comes from serving the FLAC files, and most people just want MP3s anyway, so an Opus copy wouldn’t be useful. The second time, when I suggested that I could handle everything because I see it as a fun and exciting project, the response mentioned a test of converting 200 albums to Opus. This was a small test for him with local access to the files, but a six-week slog for me without.
My tests covered the site’s top 200 most popular albums of all time, according to this listing, at the time of writing. I encoded with Opus at 96 kbps, and moved album art from track metadata into separate files to avoid duplication. I also included any art that appeared on a soundtrack’s web page but wasn’t included in track metadata, usually in their original format, but converting to JPEG XL in extreme cases like Call of Duty: Black Ops 2 which has several images weighing in at dozens of megabytes apiece. The smallest total size of these files offered by the website is 73,895 MB (usually MP3 format), the largest total size is 189,318 MB (usually FLAC format), and the total size of the Opus encodings (often including additional album art, remember) is 28,508 MB. Thus, the minimum file size reduction is about 61%, the average reduction is 78%, and the maximum reduction is 85%. See the appendices at the end of this article for a complete table of all these files.
The site owner, on the other hand, encoded his Opus test files at virtually the same bit rate as the MP3 versions, and concluded that Opus didn’t produce meaningful file size savings.
In other news, aluminum is useless because a pound of aluminum weighs just as much as a pound of steel.
At that point I gave up, and thus began my journey of enlightenment in which I gradually realized that the format wars are over and we lost.
Fair And Balanced
The fact that we lost the format wars really hit me when the Chrome team dropped experimental support for the JPEG XL image format, which will remove the option of turning on a flag that allows Chrome to display JPEG XL images. And by “the Chrome team” I mean one single program manager who, by pure coincidence I’m sure, happens to be involved in the development of AVIF, a “competing” image format. I use scare-quotes there not to suggest that AVIF is poor competition, but that it’s not a competition at all – or it shouldn’t be, anyway. Even with feature creep and parallel evolution, there remain enough distinctions to justify coexistence. Jon Sneyers, a JPEG XL developer who is extremely active and helpful in the field and its surrounding community, is always quick to note the advantages of other formats rather than pretending his project is the be-all and end-all of image formats. Rather than shooing you off to pore through Cloudinary’s collection of Dr. Sneyers’ articles (Cloudinary is his employer and a key part of JPEG XL development), Chromium issue tracker threads, and Reddit posts, I’ll summarize the situation here.
For decades now, the three main image formats used on the web have been JPEG for photographic content (real-world photos), PNG for synthetic content (screenshots, flowcharts, etc.), and GIF for animations. There are no strict boundaries enforcing this, of course; these are just the best uses of each format according to their strengths. And yes, there are animated versions of both JPEG (MJPEG) and PNG (APNG). These formats have served us well, but, surprise surprise, there’s been progress in computer science, and superior formats are available.
WebP
The first modern format to appear was WebP, created by Google and intended for photo distribution on the web. It can compress images in a lossy mode with better quality and lower file size than JPEG, and it can compress images in a lossless mode with lower file size than PNG. It also allows for GIF-like animations. The encoder and decoder are both quite fast, and the images can be displayed in any modern browser, with a smattering of support among other software. Its major problem, in my considered opinion, is that Google’s official open-source library has a really idiotic default of discarding all metadata including color profiles. There’s an option to request it to please keep that information so your converted images don’t end up lighter or darker than they’re supposed to, but that should be the default. Lossless encoding in particular should be expected not to have any loss of important information that affects the appearance of the image. Other than that, and other than its much more meager compatibility and support compared to the older legacy formats, it’s kind of nice. When its successor, WebP2, was essentially killed off (as Google is wont to do), it became clear that this format is dead in the water. It also lacks many features that are unnecessary for photos on a web page but important elsewhere, like wider color gamuts.
HEIC
HEIC is just HEVC intras in HEIF. I think that about sums it up. Right?
No.
To expand upon that, HEIF is a format that can store images, audio, or video data. When it’s used to store images that have been encoded with the HEVC codec (yes, that’s a video codec, more on that later), the result is known as an HEIC file. This was the image format that got me interested in image formats last year. I made an offhand comment about iPhone cameras using JPEG for photos, and someone corrected me: they use HEIC by default nowadays. Down that rabbit hole I went, and here we are.
HEIC might be the format with the biggest gulf between how commonly it’s used and how commonly it’s known. It’s been the default image format on iOS for several years, and I’d be surprised if more than 1% of its users knew of its existence. The format is heavily patent-encumbered, with correspondingly poor compatibility, but it’s more efficient than JPEG, and iOS uses it to reduce file sizes while maintaining the same level of image quality. The system Apple came up with is very “Apple” – it’s still a walled garden, but it communicates seamlessly and transparently with the outside world. When an iPhone user takes a picture, it’s stored as an HEIC image. When they back it up on iCloud or send it to a friend’s iPhone, nothing unusual happens. However, if they send it outside Apple’s ecosystem, such as in an email, text message, other backup service, and so on, no they don’t. Send it, that is. Their Apple device or service converts the HEIC image to JPEG on the fly, and sends the JPEG instead. The process is totally invisible to the end user. The only downside I can think of is that it can mislead people into thinking they’re working with the original image file when they’re really not, and that’s a pretty darn small downside. My dad will literally save ISO images of DVD home movies because any lossy compression would involve loss and he can’t abide that notion, and even he wasn’t bothered when I explained to him that his photo backups weren’t actually the original files. That said, this behavior is optional. You can adjust the settings to save photos with HEIC and automatically convert to JPEG when needed (the default), save photos with JPEG in the first place, or save photos with HEIC and send the original file instead of converting. I’m no fan of Apple, but I firmly believe in giving credit where credit is due, and this system works well.
AVIF
AVIF is AV1 intras in HEIF. I think we’re done here.
For real though, AVIF images are encoded with the AV1 codec. It supports lossy encoding, lossless encoding, and animations. The industry consortium backing this format is pushing it hard, but you’d be hard-pressed to find compatibility anywhere but web browsers. As with AV1, the AOM encoder is not usable due to its slow speed (several minutes to encode a single image). Even the SVT encoder is markedly slower than mature, less-efficient legacy formats, but it’s not too bad. What is bad is that FFmpeg’s latest build does offer AVIF encoding with SVT, but – surprisingly and yet somehow also obviously – the dimensions must be multiples of two, a common requirement with video codecs (some will insist on multiples of 8 or 16). For example, a height of 500 pixels is fine, but 501 would not be fine, and attempting to produce such an image with AVIF would result in an error. You have to add a filter that gives you acceptable dimensions, such as cropping out one line of pixels or scaling the image. The standalone AVIF encoder, avifenc.exe, has managed to overcome this issue and allows odd dimensions. However, it doesn’t offer SVT encoding, so it’s worthless. Harsh, but I won’t give credit where it isn’t due. The tooling is still too immature for practical consumer use, even for enthusiasts.
Hi. I’m the JPEG organization.
You may remember me from such standards as JPEG, JPEG 2000, JPEG LS, JPEG XR, JPEG XS, JPEG XT... The Joint Photographic Experts Group didn’t rest on their laurels after developing the JPEG format. They’ve developed a variety of formats for use cases that have proven less popular than cat pictures. The least obscure of the bunch is probably JPEG 2000, which has two primary uses. The first is in medical imaging, where it’s valued for its superior efficiency in lossless compression compared to PNG. The second is in digital cinema, as the format is capable of high-quality lossless animation. If you’ve watched a movie at a theater in the last several years, it was probably a JPEG 2000 image.
JPEG XL is designed as a successor to JPEG, with the “L” signifying long-term use. It’s often abbreviated to its file extension, JXL (rhymes with “pixel,” but I usually pronounce it as an initialism). The format’s specification includes many features for personal and professional use, from high bit depth support to progressive decoding (showing an image in gradually improving quality as it’s downloaded) to tiled decoding (decoding only a certain section of an image, helpful when working with very large images). Not all of the spec’s features are implemented yet, but the reference codec has just recently gotten to version 0.8 at the time of writing. Give them some time.
The format has a lossy mode, a lossless mode, and animation support, with superior efficiency and speed pretty much across the board. While codecs like AVIF are more adept at maintaining better image quality under very high compression, JPEG XL prioritizes performance with high-quality images. One of JPEG XL’s most interesting features is lossless JPEG transcoding, which starts with a regular JPEG and creates a JPEG XL image 15-25% smaller than the original, with no quality loss. The process can even be reversed to exactly reproduce the original JPEG file, basically serving as a more efficient way to transfer and store existing JPEGs without any generation loss (changes to the image resulting from resaving it in a new file with lossy compression). This makes it an easy choice for migrating an existing hoard of JPEGs to a new, more efficient format. The new, smaller files can be used as they are, or turned back into JPEGs when needed for a client that doesn’t yet support JPEG XL. Apple’s HEIC compatibility solution is good, but conversion to JPEG does result in a very slightly different image.
Generation loss
Sometimes we end up with more than a slight difference, because we’ve converted and screenshotted and reposted and rotated and resized it until the slight differences added up to a glitchy mess. There’s even a layman’s term for it: moldy memes. JPEG XL has excellent resistance to generation loss, particularly compared to JPEG, the most common format by a gargantuan margin (even for synthetic content that would be much better suited to a lossless format like PNG). Surreptitiously switching people’s photos to a superior format might actually be easier than teaching them how to properly copy files and manage their photo collections. The average consumer isn’t Ansel Adams, the 20th-century photographer reputed to spend hours waiting for the perfect moment, take one single, perfect photograph, and leave. The average consumer is a teenager who takes several photos at a time and takes screenshots of the photo gallery for easier sharing because that app has incomplete sharing options (backup on archive.org in case the original gets deleted, and how about a photo backup because I’m paranoid).
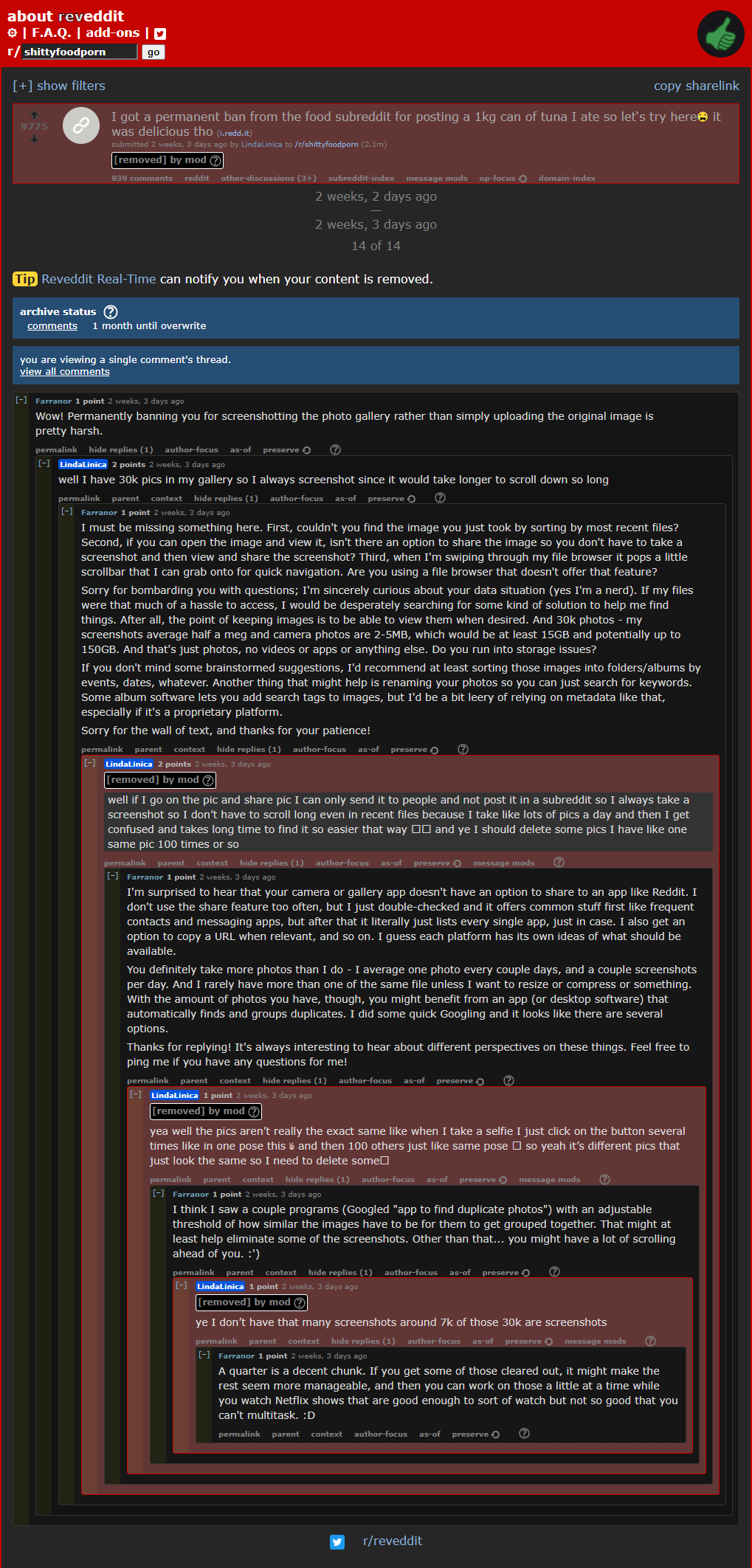{kind=link}
The result is over 30,000 images, around a quarter of which are screenshots, with up to a hundred nearly-identical versions of the same photo. The fault here lies not with the user, but with the systems that were provided. A gallery app should allow users to share photos to any app, not just messaging apps. As far as taking multiple photos where one would suffice, people have been doing that since the rise of cheap digital photography, so it shouldn’t be an unexpected use case. For a quick solution off the top of my head, how about a photo capture mode that prompts the user to snap multiple photos and then asks them to select the best one, discarding the rest. Whatever the case may be, these systems have to be designed around what users actually want to do and the way they want to do it. It’s a simple rule: “practicality beats purity.”
Fast Fashion
The design intent of long-term use also bears further examination: JPEG XL is not meant to merely supplement JPEG, but to replace it entirely, hence its combination of backward compatibility and forward thinking. Its superior efficiency, while excellent, isn’t enough for a long-term JPEG replacement – it also has new functionality to better deal with modern image-processing needs.
Sadly, this sets it apart from the video landscape, which is littered with flash-in-the-pan formats and codecs that aren’t even mature, much less in widespread use, before being discarded in favor of a younger, more attractive codec. For video, this is particularly deleterious, as its complexity and corresponding file sizes are vastly larger than those of other media, making migration a serious effort not to be undertaken lightly. And yet, new ones pop up every few years promising better quality and compression. If I tried to embrace every new video codec, I’d barely finish reencoding my library before the next one reared its head. It’s almost worse than the trend for fast fashion, meaning clothes that are meant to be worn a few times and then discarded because they’re no longer in style. We can barely give them away anymore; some African countries are even considering banning the importation of used clothing.
In the same vein, an article published just yesterday features an interview with a Qualcomm representative who suggested that they might just skip AV1 encoding (for recording videos) and wait for Versatile Video Coding, or VVC, a codec whose specifications were only finalized a few years ago. Given the massive encoding complexity of all these new video codecs juxtaposed with the necessity for real-time speed, recording directly with one of these codecs seems in my eyes to be barking up the wrong tree. Does recording in HEVC rather than AVC produce smaller files? Yes. Are they smaller than converted files that were encoded without time constraints? Absolutely not. There’s no dire need for alternative options for recording videos; we can already do that just fine. If we want to save space, the logical route at this time is to shoot videos with extreme bit rates for the highest possible quality, and then compress them afterwards. Call the original a “preview” to prevent people from getting attached to it, then process it over time and discard the original. Videos can be processed during idle periods, only while the phone is plugged in, at partial CPU loads, and so on. I’m sure that industry professionals could find a way to make this work and normalize it. It’s easier than designing new hardware, anyway.
Nature and nurture
Here’s the later when we come back to more. In an ironic twist, JPEG XL has managed to be the only modern image format that’s actually designed from the ground up as an image format. WebP is based on the VP8 video codec, WebP’s intended successor WebP2 was to be based on VP8’s intended successor VP9, HEIC is based on the HEVC video codec, and AVIF is based on the AV1 video codec. They masquerade as image formats by limiting themselves to what’s called an “intraframe,” as opposed to “interframe.” “Intra” means within, and “inter” means between, as in e.g. the global Internet vs a company’s local intranet. The meat behind a video codec’s ability to compress a video stream is that digital video doesn’t exist as a simple series of individual pictures, like an old film reel. Instead of compressing each frame independently, video codecs look for differences between frames. A sitcom with a few characters moving around a static set will result in many frames in a row that show the same scenery and props in the same place. The codec can draw that part once and then just leave it alone until it finally changes, devoting the saved bandwidth to describing the people’s movements instead.
An intraframe, also known as a keyframe, is a frame in a video that actually does contain the whole picture rather than relying on surrounding frames. They’re generally placed at scene changes or at regular intervals of five to ten seconds. An interframe is one of those efficient frames that’s compressed based on changes between frames. Thus, an image in one of these video-derived image codecs is basically just a video consisting of a single keyframe. As you might guess, the video-derived image codecs have some convenient optimizations available for adding animation to such an “image,” although it’s generally better to just make an actual video.
The problem with these video intraframe image formats is that some things are relevant for still images that aren’t a consideration for video, which precludes the possibility of those particular features. For example, early versions of HEIC and AVIF couldn’t encode an image bigger than the 4K video resolution, because HEVC and AV1 hadn’t yet needed to do so before. They got around this by packing several images into a single file, to be arranged in a grid for display. Unfortunately, it was all too easy to spot in the resulting picture where one tile ended and the next began. Fortunately, AVIF and HEIC have since been updated to handle images up to 65536 by 65536 (2 to the 16th power). Next, since each frame of a video is only visible for a small fraction of a second, it doesn’t make sense to consider the situation where it takes a few seconds to download a single frame, so they have no facility for progressive decoding. Full image formats like JPEG, PNG, and JPEG XL can quickly show a fuzzy picture and then gradually fill in the details as the rest of the image is downloaded. This isn’t always vital, but it can come in handy for users on slow or unstable connections (such as mobile data, poor reception, etc.), and a partially-downloaded image with progressive decoding can even serve as its own thumbnail, obviating the need to generate and store a second set of images.
Basically, video-derived image formats focus on quantity, while full image formats focus on quality.
But in the end, it doesn’t even matter
Because not only are short-form videos with no audio still referred to as GIFs, they often actually are GIFs. Web video has progressed by leaps and bounds, inserting a video into a web page is as easy as <video>, AVC is a perfectly serviceable video codec with essentially universal support, and yet we’re still using GIFs. There are too many people who don’t understand why not every video has to be a GIF anymore, and too many of those people are able to dictate these views to others, such as some subreddits specifically stating in the rules that no videos are allowed, only GIFs. Of course, if you upload a GIF to Reddit, Reddit will immediately transcode it back into a video that merely links to the original GIF when clicked, so if you view posts normally, you’ll never see the GIF.
Uploading a still image to Reddit is even less consistent. PNG images are maintained in their original format, JPEG images are sometimes maintained in their original format but also sometimes converted to WebP for previews, and WebP images are converted to rather low-quality JPEGs (with the exact same file size as the original WebP, in my experience). Even lossless WebP images fall victim to this mangling. It’s anyone’s guess as to why Reddit devs didn’t simply choose a preferred format and leave user uploads unchanged if they already match that format. Seriously, I have no idea why they do it this way. It makes no sense.
With malice aforethought
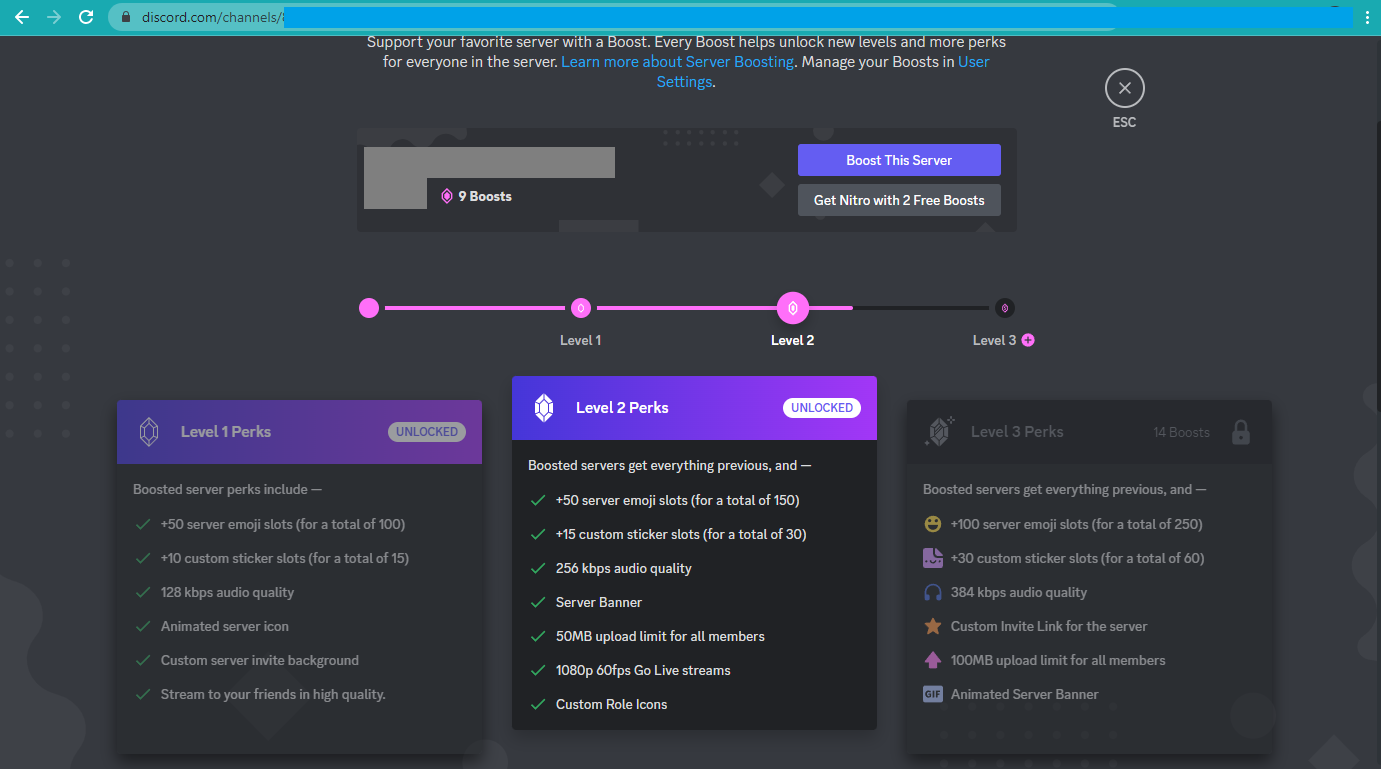
Oh, how I yearn for those halcyon times when a corporate media format decision didn’t make sense. It’s immediately obvious why Discord offers the following audio options. Just look.
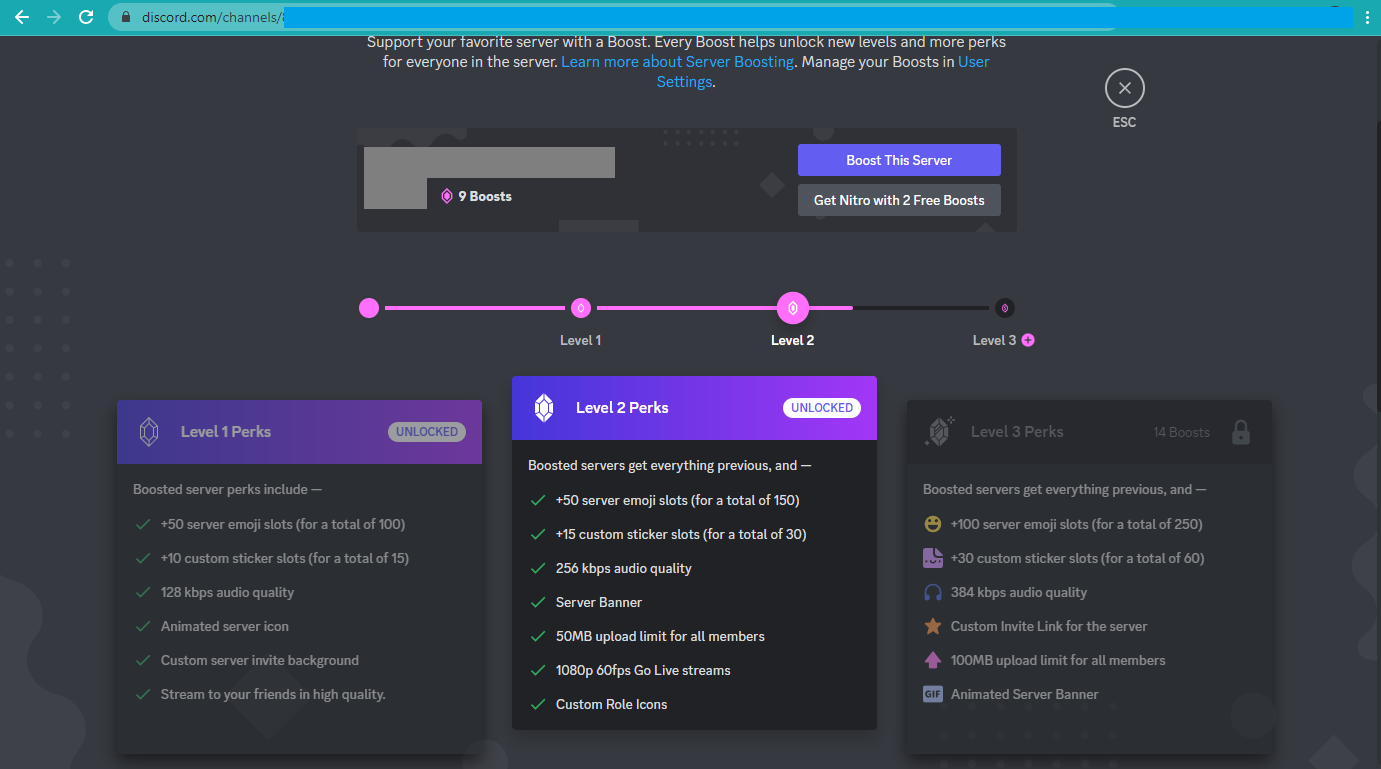
That’s a lossless WebP image, by the way. The original PNG saved in Microsoft Paint was 148 KB, the PNG saved with FFmpeg’s PNG encoder was 105 KB, the JPEG XL saved at default settings was 90 KB, the WebP shown above is 84 KB, and the JPEG XL saved at the maximum compression effort setting was 73 KB. It would’ve been nice to go with the most efficient one, but the best I could do with reasonable confidence that it would actually display in your browser was WebP, because you lost the format wars.
{kind=link}
{kind=link}
This image is from a screenshot my sister sent to me when debating whether she ought to support Discord and a server she participates in with a “boost,” which is a euphemism for money. At least it’s not “loyalty,” I suppose. Note one of the features listed as a perk: audio quality. Discord uses Opus for its audio, and the default bit rate for a free-tier server with no boosts is 64 kbps. That’s unlikely to be totally transparent (indistinguishable from the original in listening tests) for typical music, but it’s still quite good, more or less on par with MP3 at its de facto default bit rate of 128 kbps. For content that will primarily consist of speech, recorded with low-quality equipment in rooms with no acoustical considerations, it’s more than enough. If it’s not, administrators of free-tier servers can choose to increase the bit rate above the default, up to 96 kbps. Opus hits transparency for most content at that point. Discord’s “level 1 perk” for audio quality is 128 kbps, which is more or less the useful limit for two-channel (stereo) audio barring rare exceptions of complex material like harpsichord music.
Level 2 allows 256 kbps. Level 3? 384 kbps. Boost now! You need this! Transact money posthaste!
Given the choice between inexplicable format conversion decisions and blatantly misleading people into buying things they don’t need, I think I prefer the former. It’s not a comfortable choice, but we lost the format wars.
The bazaar
This is why the bazaar is more preferable to the cathedral than ever. If I were locked into the Apple ecosystem, I wouldn’t know what my phone was doing, it wouldn’t make an effort to tell me, and I would be saving nine-gig video files in my cloud storage. Well, speaking only for myself, personally, I expect I’d endeavor to learn as much as possible and do what I could with whatever tools were available and allowed. After all, my parents saved a nine-gig video file in their cloud storage, but I was able to produce a file more than 90% smaller.
Fortunately for me, I’m not locked into the Apple ecosystem. I can install whatever programs I want on my Windows PC and my Android phone, including encoders and decoders for JPEG XL, AVIF, WebP, and Opus. I can write scripts to consolidate complex processes into a simple command. I have enough freedom to manage my files on my devices, without some middle manager deciding that key features are too ugly or complex to even allow, much less provide.
My phone’s default video codec is AVC, which results in bit rates of around 14 Mbps for 1080p30 and a staggering 72 Mbps for 4K60. That’s nine megabytes for a single second of video. A recent clip I captured at this quality produced a 213 MB file for 25 seconds of video. Oh, and the audio is 256 kbps AAC for no real reason at all. It’s not like audio is difficult to encode in real time these days, so they could easily use more compression. No bit rate will compensate for terrible acoustics and microphones, anyway. It’s a tiny sliver of the overall file size, but it could’ve been better if they cared to try. Samsung phones provide an “advanced” option to record video with HEVC instead of AVC, although it has to be manually enabled while Apple devices default to HEVC. I stick with the less efficient codec in this case because it’s not worth inviting potential compatibility issues when I’ll be compressing the file myself anyway. I use VP9, because while AV1 has higher theoretical efficiency, its tooling and encoders aren’t consistently available across platforms.
A 15-second clip at 1080p30 is 50 MB as captured in AVC, and I bring that down to 8.3 MB with VP9, an 83% size reduction. The 25-second clip at 4K60 goes from 213 MB as captured in AVC to 37.6MB with VP9, an 82% size reduction. Keep in mind that not only is VP9 a more efficient codec than AVC, I’m also able to use much higher compression because I’m not constrained by the requirement to encode in real time like the capturing device is. Depending on resolution and frame rate, this compression process takes anywhere from 20 to 100 times the duration of the clip. However, I can do it on my PC or my phone, with a simple command (see the relevant appendices for Android or for Windows).
You may have noticed that encoding to VP9 saved over 90% for the nine-gig video my parents recorded in HEVC but less than 85% for my AVC clips, even though HEVC is significantly more efficient than AVC (my phone reduces the bit rate by 40% when shooting in HEVC to maintain quality comparable to AVC; I expect Apple uses similar values). This is because videos are captured at a constant bit rate, while anyone performing reencoding without real-time constraints can analyze the video to determine when it can use a lower bit rate for scenes with less motion and complexity. My clips involved a lot of camera movement, while my parents’ video captured scenes with little or no motion shot from a tripod.
I’m not dead. I feel fine!
The format wars may be over, but we’re not ready for the cart just yet. And I suppose there’s technically still an outside chance that we may eventually pull through. I know I’m doing my part: I participate in the JPEG XL subreddit, I provide friends and family with efficiently-encoded clips instead of gigantic original files, and now I’ve written this article. It’s not much, but the perfect is the enemy of the good. Maybe one day the Chromium team will listen to the requests for JPEG XL support from industry giants like Adobe and Facebook. Maybe one day Reddit will accept uploads of high-quality, efficiently-encoded files like WebP images and VP9 WebM videos as they are rather than meddling with them or outright rejecting them. Maybe one day companies like Apple will offer some kind of automatic video compression service, whether on their own servers or on users’ local devices. Maybe one day people will take an interest in this and push for improvements. Maybe I’ve convinced you to become one of those people.
We’ll see.
Appendices
Compressing on your Android phone
You’ll need to download Termux and grant it permission to install on your device. You can then enter commands to install various packages, like pkg install ffmpeg for FFmpeg, pkg install opus-tools for the standalone Opus tools, and pkg install libjxl-progs for the standalone JPEG XL tools. I also like pkg install python so I can use Python, pkg install youtube-dl for a versatile video downloader (works with more than just YouTube), and pkg install p7zip for a powerful command-line archive tool that allows you to combine files into a single archive, split a large file into multiple pieces, add password protection, and more.
Compressing audio
You can produce Opus audio at a variable bit rate targeting an average of 96 kbps with FFmpeg:
ffmpeg -hide_banner -i my_input_file.mp3 -b:a 96k my_output_file.opus
Or with the Opus reference encoder, which provides several convenient options such as --discard-pictures to remove attached images from metadata:
opusenc --bitrate 96k my_input_file.mp3 my_output_file.opus
Compressing DVD video
Here’s how to compress a DVD, which generally means a VOB file containing a 720 by 480 MPEG-2 video. I use AVC for this because MPEG-2 is a lossy codec that’s rather noisy even at a constant 10 Mbps and modern codecs really struggle with that for some reason compared to AVC. The PowerShell command:
ffmpeg -hide_banner -i .\inp.vob -fps_mode vfr -enc_time_base -1 -c:v libx264 `
-crf 22 -tune film -filter:v "yadif,scale=640:480" -c:a libopus -b:a 64k `
-strict 2 output.mp4
The -fps_mode vfr option allows FFmpeg to properly handle variable frame timings rather than forcing a constant frame rate by duplicating or dropping frames, -enc_time_base -1 attempts to ensure consistent time codes, libx264 is the technical term for FFmpeg’s AVC encoder, -crf 22 is a good efficiency compromise that yields excellent visual quality and good file size savings (you can go down to 15 for better quality or up to 30 or so for smaller files), yadif is “yet another deinterlacing filter” (for those old DVDs that use interlaced video instead of progressive video), and -strict 2 allows you to use Opus in an MP4 container. -tune film is one option that you need to keep an eye on, as this setting is only intended for film (live action). For animated content like cartoons, use -tune animation instead. Note that the backtick character ` is used in PowerShell to split a command and continue it on the next line, used here for formatting purposes.
Compressing modern video on Android
If you’re starting with a high-quality source rather than DVDs, you can use a more modern codec.
On Linux environments, such as the Termux terminal emulator for Android, I have saved the following script, with a file name of shrink_video.sh:
ffmpeg -hide_banner -i "$1" $2 -y -c:v vp9 -b:v 0 -crf 40 -quality good -speed 1 \
-an -pass 1 -f webm /dev/null
let count=1
while [ -f "${1%.*}_$count.webm" ]
do let "count++"
done
ffmpeg -hide_banner -i "$1" $2 -c:v vp9 -b:v 0 -crf 40 -quality good -speed 1 \
-c:a libopus -b:a 96k -pass 2 "${1%.*}_$count.webm"
Invoke this with a simple bash shrink_video.sh my_video.mp4 to (eventually) produce my_video.webm. If you want, you can add more options after the file name, such as rescaling your output video with bash shrink_video.sh my_video.mp4 "-filter:v scale=1280:720". Note that the backslash character \ is used in bash to split a command and continue it on the next line, used here for formatting purposes.
And here’s an explanation of a few of those options, adapted from Google’s VP9 encoding guide:
-i "$1" | Use as input the file name you provided. The quotes ensure that file names with spaces are handled properly. |
$2 | Extra arguments, if any, that you want to pass to FFmpeg. |
-y | Termux will ask if you want to overwrite the /dev/null file, which it shouldn’t bother with, so this option automatically says yes. |
-c:v vp9 | Use the VP9 codec for video. |
-b:v 0 | When you use two-pass encoding with a variable bit rate, as this script does, VP9 requires that you explicitly specify a bit rate of 0. |
-crf 40 | A constant rate factor of 40, which is basically the quality level you’re aiming for. I’ve found 40 to be good for this codec, but you can go for bigger files and higher quality by using lower values down to 30 or so, or sacrifice some quality for better compression by using higher values up to around 50. |
-quality good | A speed vs quality compromise, in between best and realtime. |
-speed 1 | Almost as high quality as -speed 0, but appreciably faster. You can go up to 4 or so if you want, but higher than that is mostly for real time encoding. |
-an | No audio. Used only on the first pass, which is only analyzing the video and not the audio. |
-pass 1|2 | 1 for the first pass which analyzes the video to look for possible optimizations and stores its findings in a log file, 2 for the second pass which actually creates the video. The second pass is much slower than the first. |
-f webm /dev/null | The output for the first pass is a temporary log file, which you can feel free to delete after everything is complete. |
let ... done | Starts a counter, assembles a file name, checks whether that file name already exists, and keeps incrementing the counter and checking until it finds a unique file name to safely use. |
-c:a libopus | Use the Opus audio codec. |
-b:a 96k | Encode audio at 96 kbps, offering excellent quality and efficiency. |
"${1%.*}_$count.webm" | The name of the new file, which adds a counter for uniqueness and replaces the old extension with webm. |
Compressing modern video on Windows
On Windows, you can use the PowerShell terminal emulator. The command has a few differences that set it apart from the Linux version. I tend to just paste this into the terminal rather than saving a script.
ffmpeg -hide_banner -i my_video.mp4 -c:v vp9 -b:v 0 -crf 40 -quality good `
-speed 1 -an -pass 1 -f null NUL; if ($?) { ffmpeg -hide_banner -i my_video.mp4 `
-c:v vp9 -b:v 0 -crf 40 -quality good -speed 1 -c:a copy -pass 2 my_video.webm }
And here’s the explanation (see Compressing modern video on Android above for the options not covered below).
-f null NUL | Store the log output of the first pass without actually creating a new file. |
if ($?) { ... } | Only execute the command in curly braces, which is the second pass, if the previous command, which is the first pass, was successful. |
Note that the backtick character ` is used in PowerShell to split a command and continue it on the next line, used here for formatting purposes.
Compressing images to JPEG XL
For JPEG XL, I recommend libjxl, the official reference implementation. You can find binary executables (software that’s ready to use right out of the box) here. There are many options, but the following are the most common:
-d 0-25for distance, meaning how much compression you want.-d 0is lossless,-d 1is visually lossless, and higher numbers offer greater compression. I tend to stick to 0 and 1, and you probably won’t want to use anything past 3. Note that it doesn’t have to be a whole number.-e 0-9for effort, meaning how many algorithms to use and to what level of detail they should run. This is basically how hard it should try to compress the file, with the primary tradeoff being encoding time rather than drastic quality differences (although there is an effect on quality in some cases). See the discussion in this thread for an explanation of what each setting does, directly from Jon Sneyers. The default setting of 7 works well.-j 0|1specifies whether JPEG input should be compressed with a lossless transcode. If you don’t use this option, the default behavior is to perform a lossless transcode when JPEG input is detected, and also notify you when that occurs. A value of 0 will treat JPEGs as any other image, useful for when you want to try higher compression or other settings. A value of 1 will perform a lossless transcode when JPEG input is detected, and not notify you when that occurs.-penables progressive decoding, which can improve the user experience on slow network connections by displaying an image whose quality gradually improves as it receives more data. In my testing, this option had a tendency to increase file sizes considerably. I don’t know whether this is expected behavior, an issue that will be resolved in future versions, or a mistake I’m making somewhere.
Compressing images to WebP
WebP images can be encoded with libwebp, Google’s reference encoder, or FFmpeg. I highly advise using the former rather than the latter, because the default behavior is to discard all metadata including important color information, and I have yet to discover how to resolve that in FFmpeg. The -o option in cwebp specifies the output file (c.f. FFmpeg in which you specify the input file with the -i option). The -metadata icc option tells cwebp to preserve color profile metadata, which is kind of important if you want the image to look right.
Lossy: cwebp -metadata icc my_image.jpg -o my_image.webp
Lossless: cwebp -metadata icc -lossless 1 my_image.png -o my_image.webp
Note that animated WebP images have better compression than equivalent GIFs and work well in a browser, but I’m aware of no tools – not even Google’s reference software – that can read in an animated WebP image for conversion into different formats or other processing.
Compressing images to AVIF
For AVIF, you’ll want something with the SVT encoder, which generally means FFmpeg on an x86 or x64 architecture (regular computer, not mobile devices or Apple Silicon). The alternatives to SVT are, as I’ve said before, unusably slow. My horrible concoction of a PowerShell script to convert all PNG images in a folder that catches odd dimensions and retries with even dimensions is as follows:
foreach ($f in Get-ChildItem *.png) {
ffmpeg -hide_banner -i $f -c libsvtav1 -crf 5 ($f.BaseName + '_crf5.avif')
if (!$?) {
ffmpeg -hide_banner -y -i $f -c libsvtav1 -crf 5 `
-filter:v scale=iw:ih+1 ($f.BaseName + '_crf5.avif')
}
if (!$?) {
ffmpeg -hide_banner -y -i $f -c libsvtav1 -crf 5 `
-filter:v scale=iw+1:ih ($f.BaseName + '_crf5.avif')
};
if (!$?) {
ffmpeg -hide_banner -y -i $f -c libsvtav1 -crf 5 `
-filter:v scale=iw+1:ih+1 ($f.BaseName + '_crf5.avif')
}
}
It’ll first attempt to simply convert the image (at a CRF of 5, which is a much lower value than used in video, because a still image needs higher quality – I’ve gotten usable results with values up to 20 or so). If that fails, it rescales the image to be one pixel taller, then tries again. If that fails, it tries one pixel wider instead. If that fails as well, it tries both one pixel taller and wider. Note that the backtick character ` is used in PowerShell to split a command and continue it on the next line, used here for formatting purposes.
Soundtrack comparison
In the following table, the first column is the identifying name of the album. For example, https://downloads.khinsider.com/game-soundtracks/album/minecraft would be minecraft. The next columns are album sizes in MP3, M4A, Ogg, and FLAC formats, as available, in megabytes (if that format wasn’t available, I’ve simply left its label in the cell). The last column is the size of the album in Opus format. Items with an asterisk * had low-quality original files, so my 96 kbps encodings may have ended up larger, if I bothered with that album at all. N.B.: I am well aware that there are actually 201 albums in the following table.
| Title | MP3 | M4A | Ogg | FLAC | Opus |
| minecraft | 349 | M4A | Ogg | 861 | 131 |
| persona-5 | 436 | M4A | Ogg | 1378 | 164 |
| the-legend-of-zelda-breath-of-the-wild | 1199 | M4A | Ogg | 2781 | 435 |
| friday-night-funkin-ost-flash | 265 | M4A | Ogg | 1201 | 92 |
| super-mario-bros | 13 | M4A | Ogg | 31 | 11 |
| persona-5-royal | 199 | M4A | Ogg | 647 | 74 |
| super-mario-64-soundtrack | 94 | M4A | Ogg | 262 | 43 |
| need-for-speed-most-wanted | 195 | M4A | Ogg | 734 | 66 |
| super-mario-3d-world-soundtrack | 283 | M4A | Ogg | 705 | 91 |
| animal-crossing-new-horizons-2020-switch-gamerip | 650 | M4A | Ogg | 1759 | 267 |
| mario-kart-wii | 256 | M4A | Ogg | 805 | 122 |
| just-shapes-beats-2018 | 242 | M4A | Ogg | FLAC | 178 |
| among-us | 18 | M4A | Ogg | 58 | 2 |
| persona-4-original-soundtrack | 344 | 839 | Ogg | FLAC | 94 |
| mario-kart-8 | 495 | M4A | Ogg | 1300 | 146 |
| five-nights-at-freddy-s-fnaf | 36 | M4A | Ogg | 39 | 15 |
| new-super-mario-bros.-wii | 289 | M4A | Ogg | 775 | 139 |
| ryu-ga-gotoku-zero-yakuza-0-ost-a-and-b-sides | 613 | 3019 | Ogg | FLAC | 148 |
| super-smash-bros.-anthology-vol.-01-super-smash-bros | 814 | M4A | Ogg | 3094 | 287 |
| animal-crossing-new-leaf | 499 | M4A | Ogg | FLAC | 235 |
| fire-emblem-three-houses-gamerip | 1004 | M4A | Ogg | 3601 | 733 |
| persona-3-original-soundtrack | 375 | 825 | Ogg | FLAC | 94 |
| super-mario-galaxy-2 | 303 | M4A | Ogg | 737 | 104 |
| earthbound-snes | 329 | M4A | Ogg | 605 | 160 |
| wii-music-collection | 72 | M4A | Ogg | FLAC | 31 |
| pokemon-diamond-and-pearl-super-music-collection | 418 | 1003 | Ogg | FLAC | 106 |
| pokemon-sword-shield-ost | 498 | M4A | Ogg | 1703 | 179 |
| harvest-moon-back-to-nature | 92 | M4A | Ogg | 284 | 36 |
| need-for-speed-underground-2 | 112 | M4A | Ogg | FLAC | 85 |
| super-mario-odyssey-original-soundtrack | 486 | 1527 | Ogg | FLAC | 186 |
| pokemon-black-and-white | 615 | M4A | Ogg | FLAC | 187 |
| plants-vs.-zombies | 120 | M4A | Ogg | 302 | 48 |
| legend-of-zelda-the-breath-of-the-wild-original-soundtrack | 745 | M4A | Ogg | 2002 | 292 |
| kingdom-hearts-iii-gamerip | 1188 | M4A | Ogg | FLAC | 419 |
| the-witcher-3-wild-hunt-extended-edition | 288 | M4A | Ogg | 748 | 87 |
| the-legend-of-zelda-skyward-sword-expanded | 1037 | M4A | Ogg | 1941 | 342 |
| castlevania-symphony-of-the-night | 160 | M4A | Ogg | 560 | 59 |
| persona-3-dancing-moon-night-persona-5-dancing-star-night-full-soundtrack | 421 | M4A | Ogg | 1426 | 151 |
| kirby-s-return-to-dream-land | 511 | M4A | Ogg | 1623 | 220 |
| dragon-ball-z-bgm | 224 | M4A | Ogg | FLAC | 99 |
| pokemon-black-and-white-2-super-music-collection | 566 | 586 | Ogg | FLAC | 187 |
| hollow-knight-original-soundtrack | 168 | M4A | Ogg | 377 | 51 |
| super-mario-world-snes-gamerip | 90 | M4A | Ogg | 166 | 55 |
| pokemon-heartgold-and-soulsilver | 599 | M4A | Ogg | 1526 | 165 |
| cuphead | 342 | M4A | Ogg | 1057 | 129 |
| super-smash-bros-brawl-gamerip | 692 | M4A | Ogg | FLAC | 485 |
| the-henry-stickmin-collection-soundtrack-2020 | 228 | M4A | Ogg | FLAC | 93 |
| geometry-dash | 28 | M4A | Ogg | FLAC | 47* |
| genshin-impact-gamerip | 585 | M4A | 1069 | FLAC | 257 |
| dark-souls-iii-soundtracks | 390 | M4A | Ogg | 1064 | 116 |
| dragon-ball-z-complete-bgm-collection | 209 | M4A | Ogg | FLAC | 158 |
| legend-of-zelda-the-twilight-princess-gamerip | 795 | M4A | Ogg | 3500 | 293 |
| shadow-fight-2 | 81 | M4A | Ogg | FLAC | 24 |
| super-mario-sunshine-game-rip | 299 | M4A | Ogg | 783 | 124 |
| brawl-stars | 210 | M4A | Ogg | FLAC | 143 |
| ace-combat-7-skies-unknown-original-soundtrack | 849 | M4A | Ogg | 2566 | 355 |
| octopath-traveler-original-soundtrack-2018 | 451 | M4A | Ogg | 1321 | 188 |
| xenoblade-chronicles | 570 | M4A | Ogg | 2034 | 271 |
| mario-kart-64 | 98 | M4A | Ogg | 280 | 37 |
| super-paper-mario | 501 | M4A | Ogg | 1343 | 159 |
| call-of-duty-modern-warfare-2 | 444 | M4A | Ogg | FLAC | 133 |
| pokemon-x-y | 421 | M4A | Ogg | 1467 | 163 |
| super-mario-3d-land | 270 | M4A | Ogg | 489 | 64 |
| persona-4-dancing-all-night | 644 | 1555 | Ogg | FLAC | 211 |
| assassin-s-creed-2 | 208 | M4A | Ogg | 600 | 82 |
| donkey-kong-country-02-diddys-kong-quest | 102 | M4A | Ogg | 315 | 46 |
| super-mario-maker-2-gamerip | 649 | M4A | Ogg | FLAC | 510 |
| digimon-themes | 456 | M4A | Ogg | FLAC | 272 |
| pokemon-omega-ruby-and-alpha-sapphire-super-music-complete-nintendo-3ds | 746 | 2345 | Ogg | FLAC | 257 |
| persona-4-the-golden-original-soundtrack | 76 | M4A | Ogg | 251 | 47 |
| pokemon-sun-moon-super-music-collection | 545 | M4A | Ogg | 1883 | 210 |
| legend-of-zelda-the-twilight-princess-hd-original-soundtrack | 379 | M4A | Ogg | 1088 | 204 |
| the-last-of-us-2013 | 95 | M4A | Ogg | 226 | 48 |
| pokemon-ruby-sapphire-music-super-complete | 326 | 835 | Ogg | FLAC | 92 |
| banjo-kazooie-complete | 1086 | M4A | Ogg | 2925 | 409 |
| donkey-kong-country-2-1995-snes | 142 | M4A | Ogg | 296 | 59 |
| super-sentai-ost | 164 | M4A | Ogg | FLAC | 105 |
| cyberpunk-2077-original-game-score | 244 | M4A | Ogg | 727 | 91 |
| donkey-kong-country-tropical-freeze-original-soundtrack | 649 | M4A | Ogg | 1964 | 271 |
| street-fighter-2-turbo | 118 | M4A | Ogg | 344 | 91 |
| mega-man-x-snes-gamerip | 94 | M4A | Ogg | 250 | 27 |
| fortnite-battle-royale-soundtrack | 87 | M4A | Ogg | FLAC | 35 |
| legend-of-zelda-the-majora-s-mask-3d-original-sound-track | 231 | M4A | Ogg | 700 | 145 |
| lord-of-the-rings-the-fellowship-of-the-ring-howard-shore | 65 | M4A | Ogg | FLAC | 53 |
| friday-night-funkin-vs.-sonic.exe-ost | 885 | M4A | Ogg | 3982 | 242 |
| streets-of-rage-remake-ultimate-soundtrack | 1343 | M4A | Ogg | FLAC | 433 |
| god-of-war-original-soundtrack | 83 | M4A | Ogg | FLAC | 41 |
| tekken-5-tekken-dark-resurrection-original-soundtrack | 390 | M4A | Ogg | 1018 | 106 |
| need-for-speed-underground-original-soundtrack | 89 | M4A | Ogg | FLAC | 67 |
| terraria-complete-soundtrack | 205 | M4A | Ogg | FLAC | 61 |
| god-of-war-playstation-soundtrack | 225 | M4A | Ogg | 416 | 56 |
| kirby-the-crystal-shards | 180 | M4A | Ogg | 578 | 63 |
| kingdom-hearts-hd-2.5-remix | 792 | M4A | Ogg | 1629 | 193 |
| friday-night-funkin-back-alley-blitz-vs.-whitty-ost-pc-mod-gamerip | 36 | M4A | Ogg | 109 | 14 |
| paper-mario-the-origami-king-gamerip | 998 | M4A | Ogg | 3588 | 355 |
| megaman-2-original-soundtrack | 32 | M4A | Ogg | 79 | 21 |
| mother-3 | 1230 | M4A | Ogg | 2481 | 299 |
| the-world-ends-with-you-twewy-soundtrack-full-collection | 726 | M4A | Ogg | FLAC | 222 |
| friday-night-funkin-gamerip | 178 | M4A | 182 | FLAC | 75 |
| hotline-miami-2-wrong-number | 378 | M4A | Ogg | 1536 | 147 |
| luigi-s-mansion-3 | 1371 | M4A | Ogg | FLAC | 445 |
| mario-kart-ds | 349 | M4A | Ogg | 1128 | 123 |
| howls-moving-castle-original-soundtrack | 97 | M4A | Ogg | FLAC | 53 |
| mario-kart-double-dash | 240 | M4A | Ogg | FLAC | 108 |
| red-dead-redemption-2-original-soundtrack | 111 | M4A | Ogg | 221 | 33 |
| splatoon-2-original-soundtrack | 421 | M4A | Ogg | 1155 | 128 |
| friday-night-funkin-b-sides-ost-pc-flash-mod | 240 | M4A | Ogg | 1580 | 91 |
| super-smash-bros.-melee-original-sound-version | 428 | M4A | Ogg | 827 | 117 |
| kirby-triple-deluxe | 382 | M4A | Ogg | 891 | 112 |
| plants-vs.-zombies-2 | 1257 | M4A | Ogg | FLAC | 294 |
| kirby-star-allies-original-soundtrack | 768 | M4A | Ogg | 2415 | 334 |
| super-mario-64-n64 | 128 | M4A | Ogg | 349 | 50 |
| god-of-war-ii-ost | 93 | M4A | Ogg | FLAC | 53 |
| assassin-s-creed-iv-black-flag | 296 | M4A | Ogg | 1744 | 114 |
| super-smash-bros.-anthology-vol.-02-super-mario | 763 | M4A | Ogg | 2854 | 277 |
| friday-night-funkin-mid-fight-masses-mod-original-soundtrack | 59 | M4A | Ogg | FLAC | 22 |
| rockman-exe-sound-box | 666 | M4A | Ogg | 2603 | 350 |
| bloodborne-original-soundtrack-2015 | 164 | M4A | Ogg | 2932 | 64 |
| wii-sports-wii | 52 | M4A | Ogg | 151 | 27 |
| ultimate-marvel-vs.-capcom-the-complete-soundtrack | 520 | M4A | Ogg | FLAC | 188 |
| pirates-of-the-caribbean-the-legend-of-jack-sparrow | 171 | M4A | Ogg | FLAC | 56 |
| friday-night-funkin-vs.-tricky-mod-gamerip | 46 | M4A | Ogg | 206 | 18 |
| paper-mario-2-the-thousand-year-door | 386 | M4A | Ogg | 1191 | 186 |
| super-mario-rpg-original-soundtrack | 203 | M4A | Ogg | 780 | 99 |
| legend-of-zelda-takt-of-wind-original-sound-tracks | 507 | M4A | Ogg | 1462 | 212 |
| pokemon-mystery-dungeon-explorers-of-sky | 717 | M4A | Ogg | 2364 | 289 |
| kirby-planet-robobot-original-soundtrack | 284 | 936 | Ogg | FLAC | 115 |
| genshin-impact-the-wind-and-the-star-traveler-2020 | 51 | M4A | Ogg | 141 | 25 |
| donkey-kong-country-returns-original-sound-version | 714 | M4A | Ogg | FLAC | 230 |
| new-super-mario-brothers | 190 | M4A | Ogg | 501 | 77 |
| monster-hunter-world-original-soundtrack | 432 | M4A | Ogg | 1274 | 153 |
| assassin-s-creed-odyssey-original-game-soundtrack | 233 | M4A | Ogg | 1398 | 92 |
| donkey-kong-country-snes | 102 | M4A | Ogg | 195 | 47 |
| bully-original-soundtrack | 217 | M4A | Ogg | FLAC | 117 |
| lion-king | 32 | M4A | Ogg | FLAC | --* |
| jojo-s-bizzare-adventure-battle-tendency-musik | 174 | M4A | Ogg | FLAC | 48 |
| guilty-gear-xrd-sign | 684 | M4A | Ogg | 1908 | 199 |
| call-of-duty-black-ops-2 | 284 | M4A | Ogg | 867 | 137 |
| crash-bandicoot-n.-sane-trilogy-complete-soundtrack | 269 | M4A | Ogg | 892 | 103 |
| mario-kart-7-original-soundtrack | 323 | M4A | Ogg | 1283 | 151 |
| ryu-ga-gotoku-kiwami-original-soundtrack | 199 | M4A | Ogg | 1533 | 67 |
| metal-gear-solid-v-original-soundtrack-2015 | 295 | M4A | Ogg | 850 | 120 |
| undertale-yellow-ost | 46 | M4A | Ogg | FLAC | 24 |
| god-of-war-3 | 113 | 362 | Ogg | FLAC | 40 |
| shadow-of-the-colossus-ost | 146 | M4A | Ogg | 2648 | 59 |
| mega-man-x4-psx | 124 | M4A | Ogg | FLAC | 44 |
| jojo-s-bizarre-adventure-2nd-season-op | 20 | M4A | Ogg | FLAC | 6 |
| persona-q2-new-cinema-labyrinth-original-soundtrack | 438 | 1471 | Ogg | FLAC | 166 |
| kingdom-hearts-hd-1.5-remix | 461 | M4A | Ogg | 1060 | 131 |
| tekken-3-playstation-soundtrack-002 | 144 | M4A | Ogg | 522 | 59 |
| splatoon-2-original-soundtrack-octotune-nintendo-switch | 247 | M4A | Ogg | 805 | 114 |
| half-life-2-official-soundtrack | 142 | M4A | Ogg | 265 | 42 |
| persona-3-fes-original-soundtrack | 135 | 346 | Ogg | FLAC | 41 |
| midnight-club-3-dubedition | 267 | M4A | Ogg | FLAC | 196 |
| castle-crashers | 106 | M4A | Ogg | FLAC | 75 |
| crash-twinsanity-original-soundtrack | 171 | M4A | Ogg | 567 | 64 |
| yakuza-like-a-dragon-unofficial-original-soundtrack-2020 | 827 | M4A | Ogg | FLAC | 258 |
| wii-shop-channel-wii | 4 | M4A | Ogg | FLAC | 2 |
| donkey-kong-64-game-music | 869 | M4A | Ogg | FLAC | 265 |
| dragon-ball-fighterz-original-sound-version | 418 | M4A | Ogg | FLAC | 205 |
| pokemon-gold-silver | 211 | M4A | Ogg | 660 | 112 |
| the-legend-of-zelda-ocarina-of-time | 101 | M4A | Ogg | FLAC | 65 |
| xenoblade-chronicles-2-original-soundtrack-type-c | 843 | M4A | Ogg | 6670 | 238 |
| pokemon-black-and-white-super-music-collection | 533 | 565 | Ogg | FLAC | 171 |
| hotline-miami | 211 | M4A | Ogg | FLAC | 76 |
| new-super-mario-bros.-u | 61 | M4A | Ogg | 164 | 30 |
| super-danganronpa-2-original-soundtrack | 403 | 1368 | Ogg | FLAC | 143 |
| my-neighbor-totoro-original-soundtrack | 55 | M4A | Ogg | FLAC | --* |
| mega-man-x6-psx | 114 | M4A | Ogg | FLAC | 38 |
| mario-party-9-soundtrack | 433 | M4A | Ogg | FLAC | 132 |
| kingdom-hearts-birth-by-sleep-358-2-days-original-soundtrack | 531 | M4A | Ogg | 1420 | 159 |
| kirby-super-star | 134 | M4A | Ogg | 324 | 58 |
| persona-4-golden-the-complete-soundtrack | 587 | M4A | Ogg | FLAC | 167 |
| minecraft-nether-update | 36 | M4A | Ogg | 83 | 15 |
| persona-3-portable-original-soundtrack | 90 | 178 | Ogg | FLAC | 21 |
| call-of-duty-zombies-chronicles-soundtrack | 297 | M4A | Ogg | FLAC | 91 |
| bowser-s-fury-original-soundtrack | 110 | M4A | Ogg | 411 | 44 |
| doki-doki-literature-club-official-soundtrack | 155 | M4A | Ogg | FLAC | 55 |
| stardew-valley | 300 | M4A | Ogg | 768 | 138 |
| kingdom-hearts-iii-re-mind-soundtrack | 211 | M4A | Ogg | FLAC | 106 |
| splatoon-original-soundtrack-splatune | 194 | M4A | Ogg | 688 | 114 |
| megaman-7-original-soundtrack | 96 | M4A | Ogg | 283 | 46 |
| tekken-7-soundtrack-plus | 671 | M4A | Ogg | 1724 | 191 |
| mario-and-luigi-bowser-s-inside-story-ost | 180 | M4A | Ogg | 609 | 67 |
| world-of-warcraft-soundtrack | 135 | M4A | Ogg | 403 | 70 |
| ultra-street-fighter-iv-original-soundtrack | 991 | M4A | Ogg | FLAC | 286 |
| ragnarok-online-original-soundtrack | 261 | M4A | Ogg | 754 | Opus |
| crash-bandicoot-ps1-soundtrack-collection | 414 | M4A | Ogg | FLAC | --* |
| paper-mario-color-splash-original-sound-version-mp3 | 327 | M4A | Ogg | 1160 | 139 |
| persona-5-scramble-the-phantom-strikers-trial-version-2020-switch | 230 | M4A | Ogg | 753 | 88 |
| rockman-x1-6-collection | 1072 | M4A | Ogg | 2430 | 247 |
| fire-emblem-awakening | 683 | M4A | Ogg | 1547 | 264 |
| shin-megami-tensei-iv-original-soundtrack | 535 | M4A | Ogg | 1961 | 206 |
| hyrule-warriors-age-of-calamity-complete-soundtrack | 846 | M4A | Ogg | 2536 | 291 |
| kidou-senshi-gundam-extreme-vs.-full-boost-premium-g-sound-edition | 656 | M4A | Ogg | FLAC | 200 |
| a-hat-in-time-ost | 593 | M4A | Ogg | 2141 | 233 |
| street-fighter-ii-the-definitive-soundtrack | 309 | M4A | Ogg | 1912 | 116 |
| persona-5-strikers-original-soundtrack-2020 | 309 | M4A | Ogg | 1189 | 124 |
| pokemon-firered-leafgreen-music-super-complete | 224 | M4A | Ogg | 836 | 127 |
| pokemon-red-green-blue-yellow | 108 | M4A | Ogg | 330 | 56 |
{kind=link}
{kind=link}